Point-source emissions processing in SMOKE focuses on converting annual, daily, or hourly emissions to hourly, gridded model-ready emissions of the chemical species used by an AQM. Recall that by “point sources” in SMOKE we mean point sources in the usual sense plus wildfires with/without precomputed plumes. SMOKE processing may be performed either with or without growth and control of emissions. SMOKE can process both criteria and toxics inventories for point sources and combine consistent criteria and toxics inventories in one run (as explained in more detail in Section 2.8.5, “Combine toxics and criteria inventories”).
Point-source processing can be performed using a CMAQ-based approach or a UAM-based approach, as previously described in Section 2.4.3, “Model-ready files”. The processing steps for CMAQ base-year processing are shown in Figure 2.15, “Base case point-source processing steps for the CMAQ-based approach”. In Figure 2.4, “Parallel approach to emissions processing”, we also included the major intermediate vectors and matrices; please refer to that diagram for those details.
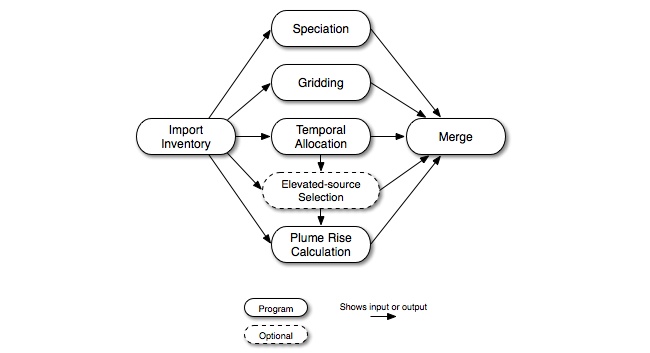
The inventory import step reads the raw emissions data, screens them, processes them, and converts the data to the SMOKE intermediate inventory file (inventory vectors in Figure 2.4, “Parallel approach to emissions processing”). The import can optionally include day-specific and hour-specific data. The emissions in the inventory file are subdivided to hourly emissions during temporal allocation; assigned chemical speciation factors during speciation, and assigned spatial allocation factors during gridding. The plume-rise computation estimates vertical plume rise of emissions sources and computes the fraction of emissions from the sources to go into the model layers. The results of these steps are combined in a merge step, which creates model-ready files for CMAQ.
Users may optionally choose to select specific sources to be elevated sources and/or PinG sources. If this approach is taken, the selection process can depend on daily-total emissions summed from the Temporal output files. Hence, Figure 2.15, “Base case point-source processing steps for the CMAQ-based approach” shows that the elevated-source selection may optionally depend on the output from the Temporal program. If elevated-source selection is being included, the plume-rise computation uses that information to skip the point sources that have not been selected as elevated. Thus, plume rise is only computed for the elevated sources. The elevated-source selection also provides its results to the merge step, which is where the special PinG data files for CMAQ are created in addition to the 3-D model-ready file.
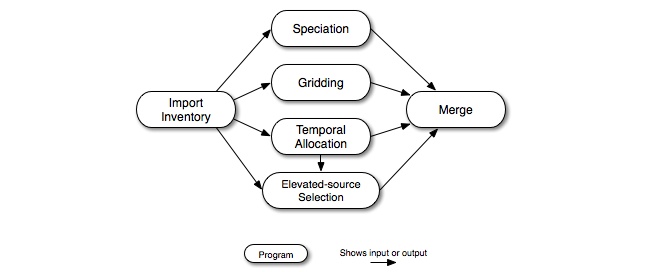
Figure 2.16, “Base case point-source processing steps for the UAM-based approach” describes base-case processing for the UAM-based approach. For this type of modeling, the elevated-source selection step is required, and the plume rise computation is not performed. Otherwise, the major processing steps are the same as for the CMAQ-based approach.
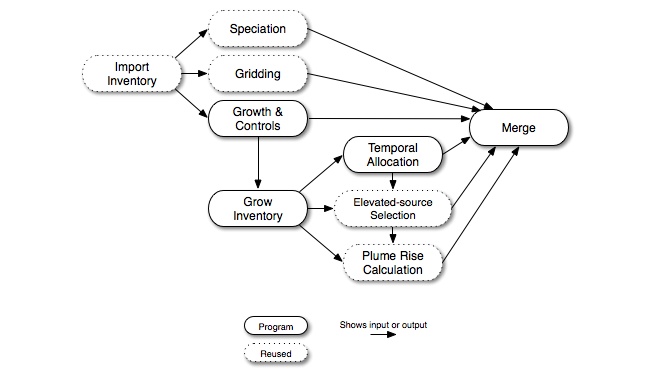
In Figure 2.17, “Future- or past-year growth and control point-source processing steps for the CMAQ-based approach”, we show the point-source CMAQ-based processing steps for future- or past-year processing. This processing is similar to the base-year processing flow, except the growth and controls step in added to calculate the growth and control matrices. The grow inventory step is added to convert the inventory from the base year to a future or past year. The control matrix can optionally be merged to apply control factors to the future- or past-year emissions. The steps shown with dotted lines represent steps that can be reused from the base-year processing because they do not necessarily depend on any of the new steps. However, if the elevated-source selection is to be performed based on the grown emissions, then the elevated-source selection and plume rise computation steps would need to be redone. Note that usually the same elevated-source list is used in both the base- and future-year modeling.
Figure 2.17. Future- or past-year growth and control point-source processing steps for the CMAQ-based approach
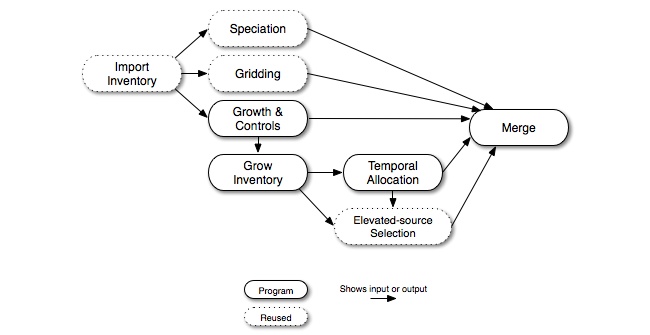
Growth and control can also be used for UAM-based processing (Figure 2.18, “Future- or past-year growth and control point-source processing steps for the UAM-based approach”). As with the other figures, the dotted lines indicate steps that may be reused from the base-case processing. If the elevated-source selection depends on the grown emissions then you will need to regenerate the elevated-source list, though it is the usual practice in modeling to use the same elevated-source list in both the base- and future-year modeling. This allows the air quality modeling results to be more comparable.
Figure 2.18. Future- or past-year growth and control point-source processing steps for the UAM-based approach
As with area sources, you may apply many growth and control matrices at the front end of processing. The area-source diagram for this approach was provided as Figure 2.10, “Alternative future- or past-year growth and control area-processing steps”, and the point-source approach is quite similar, with the addition of the elevated-source selection and plume rise computation steps.
In sections later in this chapter, we describe the SMOKE programs that are needed for each of the processing steps just discussed and additional details about what activities are accomplished during each step. These sections are:
- Section 2.8, “Inventory import”
- Section 2.9, “Temporal processing”
- Section 2.10, “Chemical speciation processing”
- Section 2.11, “Spatial processing”
- Section 2.12, “Growth processing”
- Section 2.13, “Control processing”
- Section 2.14, “Elevated-source processing”
- Section 2.17, “Creating model-ready emissions”
- Section 2.19, “Quality assurance”
Point-source processing includes a number of additional features that are not applicable for other SMOKE source categories:
- Flexible source definitions
- Stack parameters
- Day- and hour-specific emissions
- Different approaches for elevated sources for different AQMs, including the use of PinG sources
- Elevated-source selection
- Wild and prescribed fires point sources
Depending on the input format of the point-source emissions (e.g., FF10, ORL), the set of characteristics that are used to uniquely identify a point source can be different. For example, the ORL-formatted inventories define a point source using a country, state, and county code, an SCC, a plant identifier, a stack number, a point identifier, and a segment number. The FF10 format, however, identifies a source using a FIPS state/county code, a plant code, a unit ID, a segment ID, and SCC. To better support the formats and be adaptable if new formats are created in the future, SMOKE uses a flexible definition of point sources. This definition consists of the following source characteristics to uniquely define the sources:
-
Country, state, and county code
-
Plant ID (15 characters or less)
-
Characteristics 1 through 5 (each 15 characters or less)
Depending on the input format, SMOKE assigns different variables from the input format to the parts of the SMOKE point-source definition. The assignments for the remaining characteristics are as follows:
ORL format:
- Char 1: Point ID
- Char 2: Stack ID
- Char 3: Segment ID
- Char 4: SCC
- Char 5: unused
FF10 format:
- Char 1: Stack ID
- Char 2: Unit ID
- Char 3: Segment ID
- Char 4: SCC
- Char 5: unused
The meaning of these source characteristics for a given inventory type needs to be considered when cross-reference files are created, if cross-reference entries other than state/county and SCC-specific entries are provided.
As just described, SMOKE uses a flexible definition of point sources. This definition may or may not include the SCC (although SCC is always at least a source attribute). Cross-reference files for point sources can contain source-specific records, and they usually use the SCC to perform the needed assignments during emissions processing. For the files to be self-describing, they use a header that indicates the number of characteristics in addition to the plant ID that are being used in the cross-reference file. This number needs to be consistent with the number of point-source characteristics used in the inventory files. In addition, the header indicates which, if any, of the point-source characteristics is the SCC. This header starts with the characters /POINT DEFN/, and the files that use it describe it as part of the file format definition in Chapter 6, SMOKE Input Files.
Several of the source attributes for point sources are stack parameters - specifically, the stack height, stack diameter, and the stack flue gas exit temperature, velocity, and flow rate. SMOKE can use hourly data for the stack flue gas exit temperature, velocity, and flow rate when using the CMAQ-based approach to modeling with SMOKE computing hourly plume rise. The hourly stack parameters cannot be used when modeling using a UAM-based elevated-point-source approach.
During the Smkinven program’s import of the stack parameters from the annual or average-day inventory file (i.e., not the hourly stack parameters), SMOKE needs to read or assign stack parameters for all point sources. Section 2.8.9, “Fill in and check point-source stack parameters” explains in greater detail what the Smkinven program does with stack parameters. The hourly stack parameters are read in without modification or adjustment.
Emissions from point sources are sometimes available as day- or hour-specific values. Smkinven can import the day- and hour-specific data, and it can also convert the hour-specific data to hour-specific temporal profiles. When these data are available, the Temporal program overrides the annual or daily emissions with the most specific data available. If day-specific data are available, Temporal uses them to overwrite the annual or average-day emissions during the time periods that these data are available. If hour-specific data are available, Temporal uses them to overwrite the annual, average-day emissions, or day-specific emissions data.
As introduced in Section 2.4.3, “Model-ready files”, there are two different major approaches for creating emissions inputs to AQMs: the CMAQ-based approach and the UAM-based approach. The two approaches differ only on how point sources are being treated. In the CMAQ-based approach, SMOKE calculates the plume rise using an algorithm based on a Briggs plume rise formulation. SMOKE then includes the vertical distribution of the point-source emissions in the 3-D model-ready file for CMAQ. For the CMAQ model only, SMOKE can also create two special PinG files: one to identify the sources, their locations, and their stack parameters, and the other to provide the hour-specific emissions for just these sources. In the UAM-based approach, SMOKE creates a special elevated-point-source file that both identifies the elevated and PinG sources and includes the hourly emissions values for those sources.
PinG sources are those sources that will be treated in greater detail by the AQM. In simple terms, the AQMs preprocess the chemistry of the plume emissions before those emissions are provided to the AQM grid cells and layers. The intent of the PinG approach is to provide more accurate modeling at and around very large point sources.
Section 2.14, “Elevated-source processing” describes in greater detail the steps taken by SMOKE in the layer fraction processing using a Briggs formulation and the elevated and PinG source selection.
You may also either provide either precomputed point-source plume rise to SMOKE or internally compute plume rise using acres burned and fuel loading of fires with both the CMAQ-based and UAM-based approaches to modeling point sources. Precomputed plume rise point sources are called explicit plume sources. This capability was implemented for modeling wildfire sources as point sources in SMOKE using plume rise computed with a different approach from the Briggs-based approach used for stack-based plumes. The input data for this approach are the fraction of emissions in layer 1, the bottom of the plume, and the top of the plume. SMOKE distributes the emissions across the layers by weighting the emissions by the pressure difference in each layer over the total pressure difference between the top and bottom of the plume.
For the UAM-based modeling approach, the file format does not readily allow you to provide precomputed plume rise; in fact, the entire premise of the format is that the AQM will compute the plume rise. To enable you to provide precomputed rise for the UAM-based modeling approach, the Smkmerge program creates an ASCII elevated-point-source file with an imaginary stack for each layer of each source (e.g., each wildfire). The stack parameters of the imaginary stack are set to values that will ensure a zero plume rise will be computed for the stack, and the x-y location of the stacks are the same for all imaginary stacks representing the same source. The emissions associated with the imaginary stacks are provided based on the emissions values that are to be entered in each layer for the source. The emissions for layer 1 are written in the point-source file to the imaginary stack associated with layer 1, and the same is done for all of the other layers. SMOKE uses a zero value for the imaginary stack when the emissions from a given source are not in a layer for an hour or when the source stops (e.g., once a wildfire ends). While not particularly elegant, this approach permits providing precomputed plume rise to the UAM-based models without having to change those models.