When Smkinven reads an inventory, it also puts its sources into a special sorted order prior to outputting the SMOKE intermediate inventory
files. All programs that read Smkinven outputs, which includes most of the SMOKE programs, expect this order. The order is determined by sorting the source characteristics
listed in Section 2.7.1, “Summary of SMOKE processing categories” in ascending order. For example, area sources will be sorted in order of increasing country/state/county code, and within
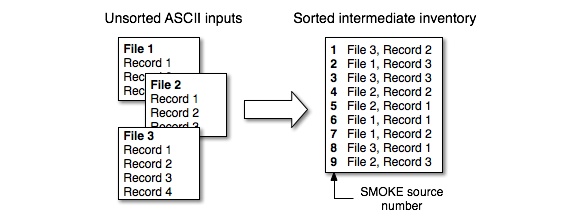
a single country/state/county code will be sorted in order of increasing SCC. In Figure 2.19, “Combining and sorting ASCII inputs to created sorted I/O API outputs”, we show how the sorted order may be completely different from the order of the files and records provided to Smkinven. The figure shows the unsorted ASCII input files at left (provided to Smkinven by logical files ARINV, MBINV, or PTINV) and how the records can be rearranged by Smkinven to create the sorted I/O API output files (output from Smkinven as AREA, MOBL, or PNTS). Each record in this diagram represents a complete inventory record with all source characteristics, source attributes,
and emissions.
Having this sorted order is important because the programs that depend on Smkinven outputs also store their outputs in the same order. However, these other programs (such as Temporal for temporal allocation, Spcmat for chemical speciation, and Grdmat for spatial allocation) store their records using the record numbers to match their outputs with the Smkinven outputs. This means that the source characteristics that are stored in the Smkinven outputs are not also included in the outputs from Temporal, Spcmat, Grdmat and other programs; these programs rely on the sorted order in the Smkinven outputs not changing. This approach allows minimal redundant data storage, this reducing disk space needs.
As explained previously, the records output from Smkinven are vectors of emissions and source characteristics that make up the SMOKE intermediate inventory files. Each record number in the file identifies an element of the vector. The outputs from Temporal are also vectors of hourly emissions. The record number in each hourly vector will match the record number in the intermediate inventory files. The outputs from Spcmat are a matrix of speciation factors, in which the record numbers (rows of the matrix) will match the record numbers of the intermediate inventory files. The columns of the matrix are each valid pollutant-to-species transformations. The outputs from Grdmat are a sparse matrix, but again the rows of the matrix match the rows of the intermediate inventory file. Therefore, assignment of factors is a simple matter of selecting the same record number from the Smkinven output files; this is in fact one part of the vector-matrix multiplication used by SMOKE.
It is important to remember this sorted-order approach when you have run an inventory through all of the programs once, and then want to change your inventory and re-import the data with Smkinven. For the re-importing and subsequent rerun, if any source characteristics in the inventory change, or if any sources are added or removed, then the number and/or order of the output sources in the new Smkinven outputs will be different. This means that the outputs from all processing steps that depend on the Smkinven outputs will need to be rerun.